
…the continuing adventures of extract refreshing in Tableau-land. For an admittedly dry kickoff to this story, read Part I.
Extract Refreshing: What do you want?
In the previous post, I asked you to decide what’s important.
- Do you need to get as many extracts processed as possible?
- Or, is the goal to get fewer extracts refreshed super-duper fast.
Reality check
Unless you can deploy significant hardware (or have a workload which happens to cooperate), you may not get both. We’ll dive into this much more deeply in Part III, but you’ll start to see what’s coming in a minute or two.
If you’re focusing on increasing overall throughput on your system, you’ll likely pay more attention to Transactions Per Second (TPS).
I measured TPS like so:
- Use an LOD calc to capture the Started At time of the very first extract that hits the queue during the test
- Use another LOD calc to capture the Completed time of the last extract in the test’s batch of extracts
- Datediff the two and use this value to divide the total number of extracts (success or failure) completed during the test
This approach has a couple wrinkles:
Some may not consider a failed extract refresh as a transaction that should be counted. It doesn’t matter what your TPS is if you’re getting tons of failures, one might reason. To me a transaction is a transaction is a transaction, though.
The mechanism I use to queue up refresh jobs executes X (~1000 for the purposes of what we’re talking about) refresh transactions. It does so using specific proportions of x-small / small / medium / large / x-large / xx-large / xxx-large refreshes. The order in which those jobs are introduced is random, however.
I’m trying to duplicate some of the behavior of the jokers (you know who you are) who go into Server and randomly hit “Refresh extract right now” because they can’t wait for their scheduled job to execute. I admit I’m one of those people. The self-loathing is palpable.
The upshot of this is that if 3-4 of the “really long running” extract refreshes happen to land at the end of the test, it’ll sort of be “artificially” extended. There might be a period when only 3-4 things are going on in the system and there are a BUNCH of free backgrounders that would normally be doing work. This drives down your TPS which would otherwise be higher if all the backgrounders were churning away. I saw variation in the neighborhood of one-to-two percent (as high as three) when I ran the same tests over and over.
Runtime
Runtime is easy: Completed – Start Time. If your goal is to get (fewer) specific extracts processed ASAP, you’ll care about this.
Reveal #1 What instance types are best?
Let’s get this out of the way early. The best I found was the compute-optimized C4.
Note that the C4 is not the instance type I would generally choose for an all-purpose Tableau box. That’s because It has somewhere between ½ to as little as ¼ of the RAM compared to a like M4 or R4.
At the start of my testing, I actually had guessed that limited RAM would negatively impact refreshing on C4s since conventional wisdom says “Give your backgrounder machine lots of memory”. In my testing, it really didn’t seem matter that much, though. It looks like C4s are great when we’re talking about extract refreshing only.
In just about every test I tried, the C4 configured with “X” vCPUs (whatever X happens to be) beat other instance types with the same number of vCPUs. The C4 delivered higher TPS and, lower runtime, and lower total execution time (run time + wait time in the queue).
Example
Our Server Admin Guide recommends you take the number of cores you have on an “extract only” machine and divide by two in order to calculate the number of backgrounder processes you should run.
In the next post I’ll show you some situations where you might ignore this guidance, but let’s start off by following the rule book. We’ll look at two 8-core (16 vCPU) machines which act as backgrounder boxes, plus a primary which does nothing useful. Each of these two machines will run 4 backgrounder processes, for a total of eight.

The c4 refreshed 995 extracts in 382 minutes, compared to an average of 408 minutes and a max (for the r4) of 425 minutes.
The c4 delivers TPS of .0434, which is about 9-10% higher than the m4 or r4:

That’s not the whole story, though. If you scroll back up and look at the Runtime per Extract Type (sec) stacked bar, it’s pretty clear there’s some variation in terms of the amount of time certain types of extracts took to refresh on one machine type vs another. Let’s drill and look at the C4 vs. the M4:
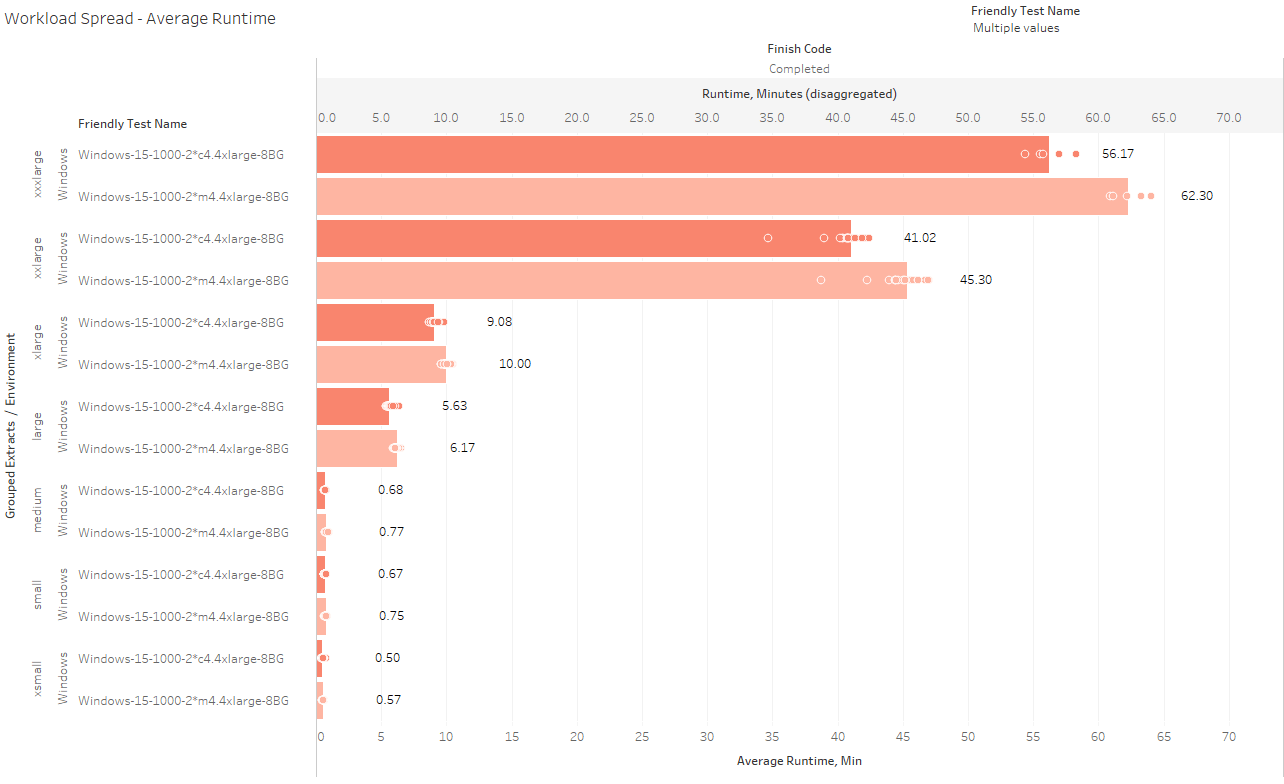
For each extract type in my workload, the C4 was better. Some of the differences may look small, but look at them in terms of a percent difference:
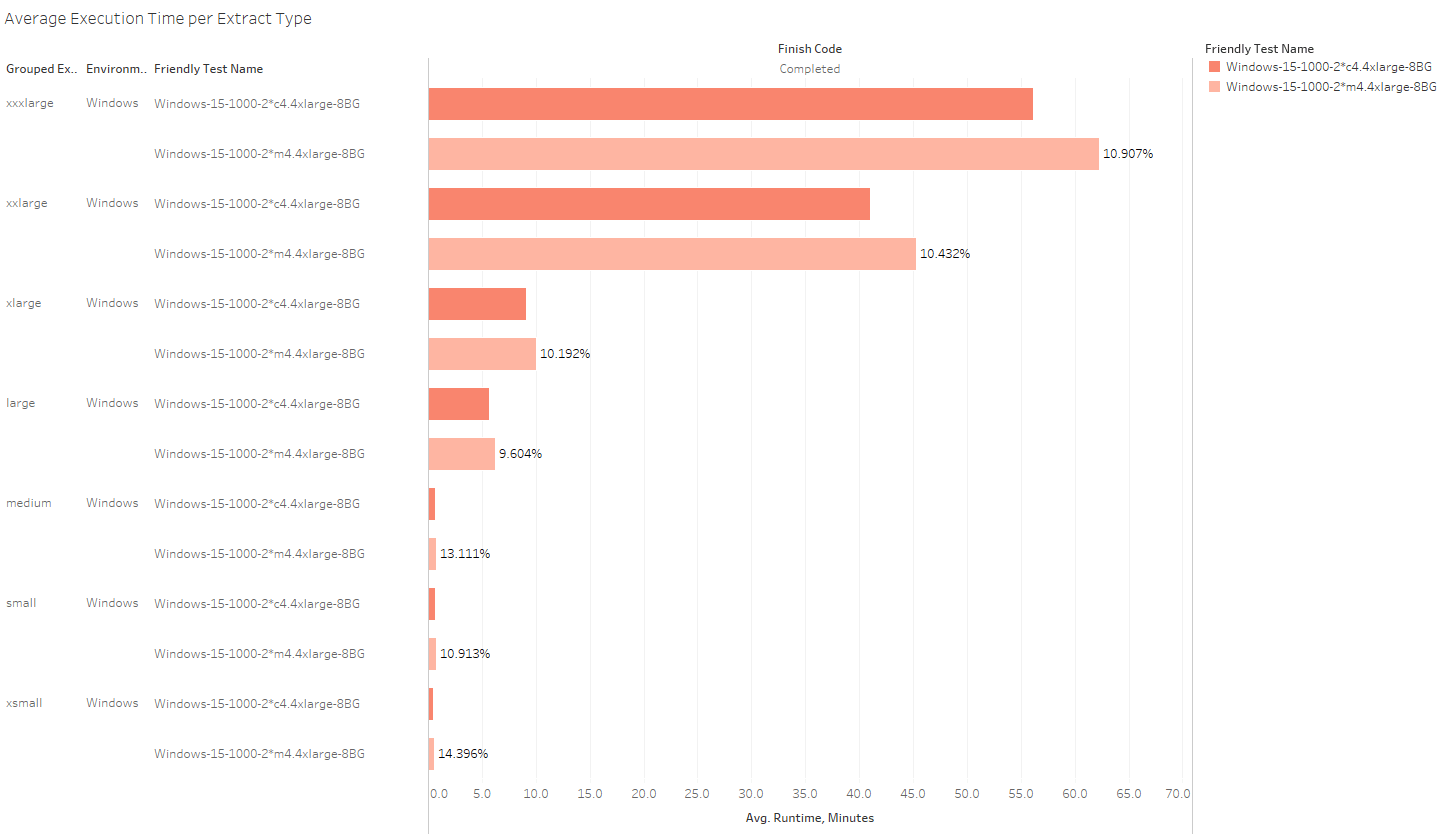
The M4 is up to 14% slower than the C4 on the type of transaction I have the most of. In terms of driving up my TPS, I need the x-small workbooks to “go fast” since they get executed the most often. The C4 does that for me.
When you look at the runtime results for the R4, it quickly becomes apparent that it’s much worse at “big” extract refreshes, but much better at the smallest-of-small:
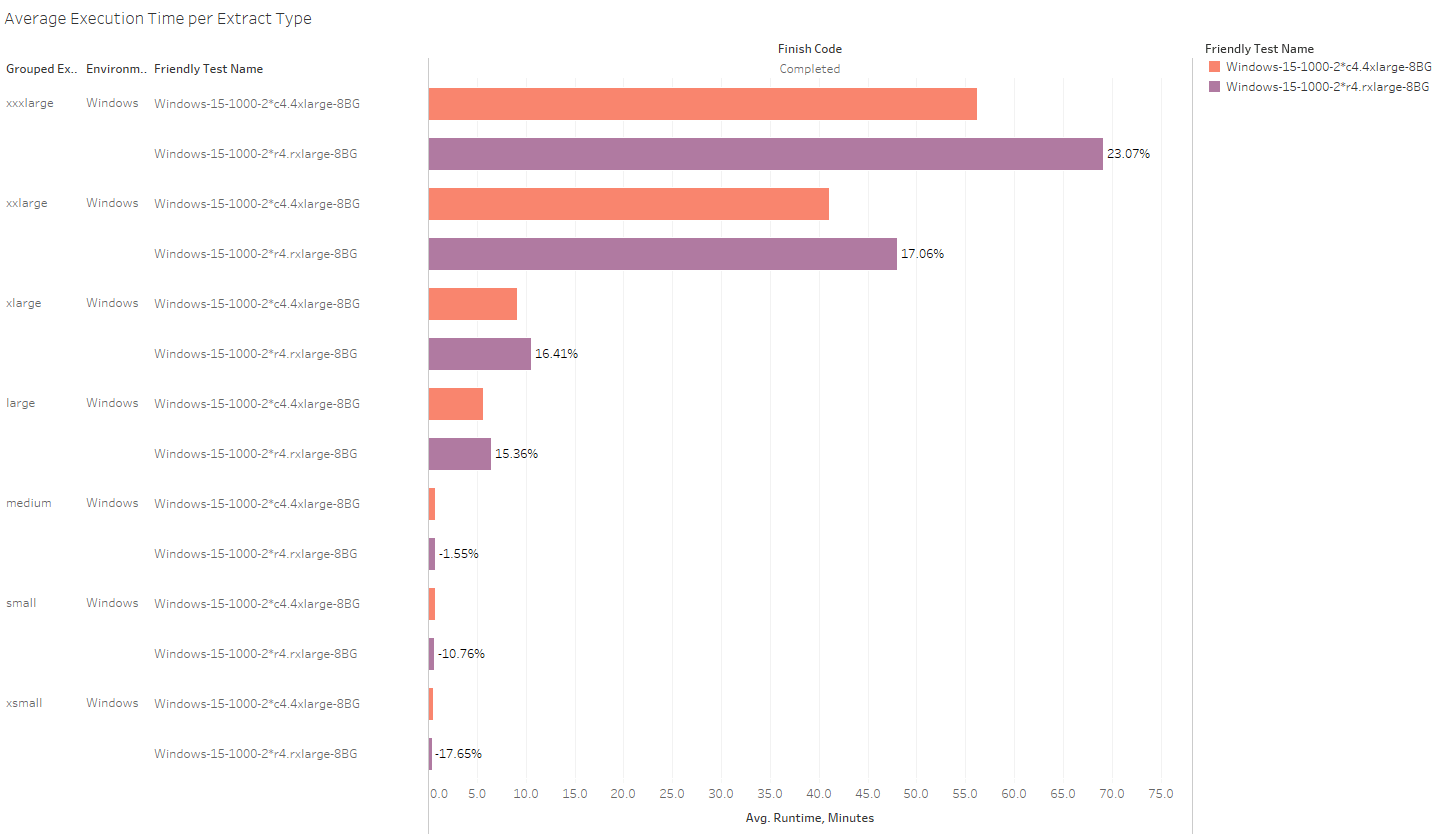
Unfortunately for the R4, the relatively poor performance of larger extracts effectively canceled out the advantage it had on smaller extracts.

Warning: Don’t assume that the behavior you see in ONE topology will be the same you see in another. We’ll get into that more next time, but here’s a pretty good example: We’re looking at the same two R4 machines, but now they’re running 12 backgrounders each (yes, twelve each) for a total of 24:
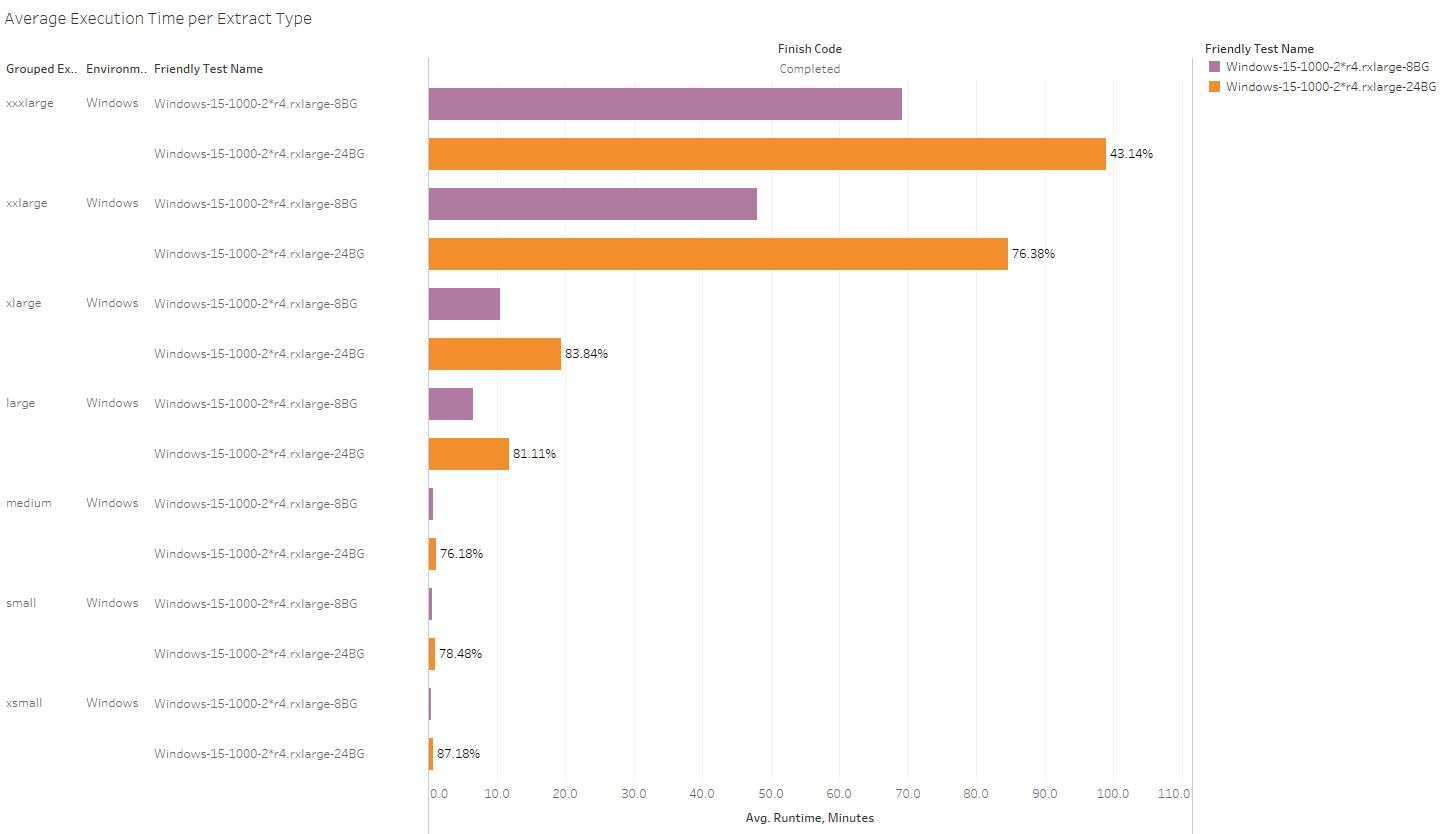
The “burdened” R4s with 12 backgrounders are slower to refresh BOTH the big and small workbooks now. You’ll ultimately get MORE workbooks refreshed with the highly-parallel-but-overburdened 12 backgrounder machines, but the “cost” is that your runtime-per execution goes up.
How long do I wait?
Remember that we’re adding 15 extract jobs / minute to be processed. The result is that we build up a queue pretty darn quickly:

It’s interesting to see how FAST we get through that queue, though. Here’s how long a job (on average) waited in the queue before being serviced. Again, C4 is our champ:

Here’s the same information broken down by the type of extract. Queue time is all over the place, but generally “lower-ish” on the C4s.

Miscellany
i3 Instance Types
I forgot to mention the I3, which is AWS’s storage-optimized instance type. I was hopeful that its super-fast local storage might do something wonderful for extract creation since we land a lot of temporary data to disk. The goal was to see if “forcing” Tableau Server to work on instance store volumes would be worthwhile.
I striped two ephemeral disks on my I3s into a single volume in much the same one would work with EBS GP2 volumes. Then, I used fio to run a stress test. I went with 70/30 random read-writes using 8K blocks. Anyway, I got 159K IOPS and > 1300 MBpS throughput. Holy snikes!
I then symlinked each backgrounder’s \tableau folder to the super-fast volume. Results:
- In a vacuum (using Desktop), workbooks refreshed in ±5% the time of other instances
- In throughput tests, the amount of IO generated by 6-8 backgrounder processes wasn’t really enough to “wear out” the more basic EBS GP2 volumes. CPU was the bottleneck for my tests, not disk throughput
- Typically, refresh performance resembled what I saw on R4s.
I ended up having built an awesome IO awesome solution when IO wasn’t something that needed solving. Damn.
Storage
Forgot to mention what the disk subsystem on these test machines looked like. Shame on me.
- Each machine ran EBS GP2 SSDs
- OS on C: (~50 GB)
- Tableau on D: (100 GB, 300 base IOPS with ability to burst to 3K)
The backgrounders seemed to be quite happy with this arrangement. I very rarely saw disk latency of > 20ms during a test. If there was a problem anywhere it was the Primary, which hosted my single file store. As Data Engines on 2-4 backgrounder machines “handed off” their newly refreshed extracts for storage on the Primary, I sometimes saw relatively high latency on the Primary’s disk of between 20-50ms. Next time I do this I’ll probably “enforce” disk throughput on the Primary.
Next time
Now that we’ve gotten the basics out of the way, we’ll go deeper:
- What is the best topology to deploy x cores in to drive high TPS?
- More or less backgrounders?
- Should I scale up or out?
And more:)